
はじめに
メリークリスマス!今年新卒で入社したK.Mです!昨日から今日まで弊社では、開発部でテックカンファレンスが開催されていました!かくいう私も運営&登壇者として参加させていただき、ドタバタしつつも非常に有意義な時間を過ごすことができました!そんな状態でしたが、今年の集大成としてフロントエンド×バックエンド×AIを使ったローカルで動く簡単なWebアプリを作ってみたのでご紹介したいと思います!
概要
アプリ概要
今回は、日本語を英語に翻訳するWebアプリを作成しました。ざっくりとした概略図を以下に示します。
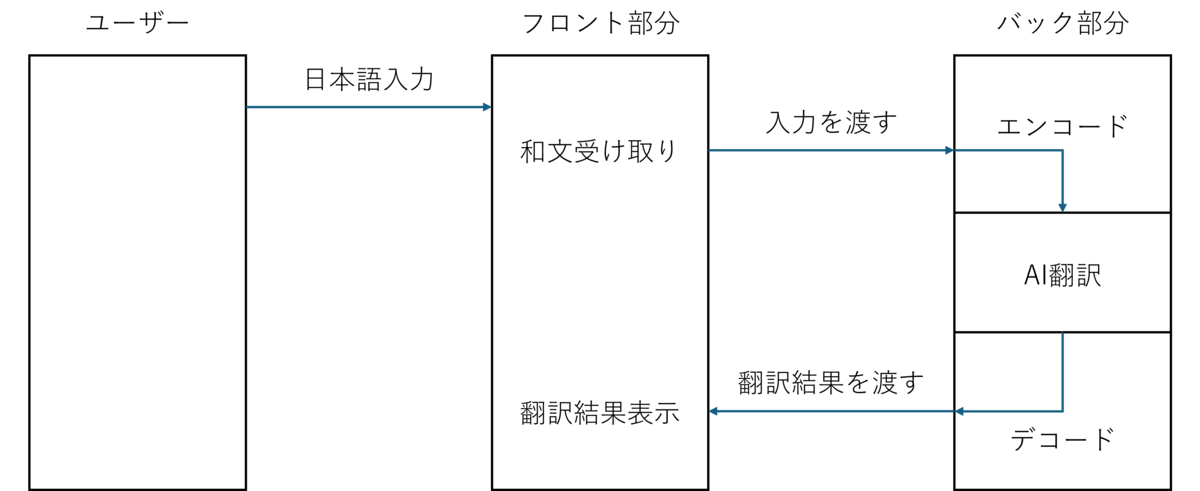
まずはフロント部分で翻訳したい日本語を受け取ります。翻訳ボタンを押すと、FastAPIで作成したエンドポイントに受け取った日本語が送られます。その日本語をもとに、Hugging Faceに公開されている翻訳モデルを使って英語に翻訳しフロント部分に返して翻訳結果を表示します!
使用技術
タイトルにもありますがフロント部分をReactで実装し、AIモデルで翻訳を行う処理はPythonで実装しました。翻訳の処理をAPIとして呼び出すために、Webフレームワークの一つであるFastAPIを使用しました。最後に、アプリの根幹である翻訳モデルについてはHugging Faceで公開されているモデルを使用しました。
フロントの実装
Viteを使ったプロジェクト作成
今回はビルドツールとしてViteを使ってフロント部分を実装していきました。コマンドでnpm create vite@latestを実行し、プロジェクト名をFrontEnd、言語はReact+TypeScriptで環境構築しました。cssは割愛しますが、フロントについては以下のように実装しました!
import { useState } from 'react' import './App.css' interface Content { translate : string } function App() { const END_POINT = "<エンドポイントのURL>" const [translateText , setTranslateText] = useState("") const [displayText , setDisplayText] = useState("") const request = async (url : string) : Promise<Content>=>{ return new Promise((resolve,reject)=>{ fetch(url) .then((res)=>res.json()) .then((data)=>{resolve(data)}) .catch((error) => reject(error)) }) } const requestHandler = async (url : string , translateText : string) => { const reqUrl = url + "?content=" + translateText const result = await request(reqUrl) setDisplayText(result.translate) } return ( <div className='container'> <h1>英訳したい日本語を入れてください。</h1> <div className="card"> <textarea className='textarea' onChange={(e)=>setTranslateText(e.target.value)}/> <button onClick={()=>{ requestHandler(END_POINT , translateText) }}>翻訳</button> </div> <p className="read-the-docs"> {displayText ? displayText : "ここに英語が表示されます"} </p> </div> ) } export default App
今回はシンプルに
- 日本語を入力する箇所
- 翻訳ボタン
- 翻訳結果を表示する
以上3つのみを実装しました(シンプルすぎてほとんど実装をしていません・・・😅)
また、const END_POINT = "<エンドポイントのURL>"の箇所について、今回ローカルで動かすのでこちらにべた書きしていますが、実際にデプロイする場合は.env等の環境設定ファイルに記載しましょう。
APIの実装
ライブラリのインストール
続いて、翻訳を行うAPI部分の実装を行います。今回使用するFastAPIおよびHugging FaceのAIモデルは外部ライブラリなの、以下のコマンドを使ってインストールしていきます。
pip install fast api uvicornとpip install transformerspip install sentencepiecepip install pytorch torchvision torchaudio cpuonly -c pytorch
もしここまででエラーが出た場合、 過去にpipでインストールしたライブラリとで依存関係の競合が起きている可能性があります。今回私はGitHub CodeSpaceを使っていたので特に問題なく進みましたが、エラーが出た方はAnacondaを使って仮想環境を構築するか、CodeSpaceを使うことをお勧めします!(個人的には環境のスクラップ&ビルドがしやすいCodeSpeceをお勧めします!)
バックの実装
続いてFrontEndディレクトリと同階層にBackEndディレクトリを作成し、その直下にmain.pyファイルを作成します。その中に以下のように実装を行いました。
from fastapi import FastAPI from fastapi.middleware.cors import CORSMiddleware from transformers import MarianMTModel, MarianTokenizer app = FastAPI() app.add_middleware( CORSMiddleware, allow_origins=["*"], # すべてのオリジンを許可 allow_methods=["*"], # すべてのHTTPメソッドを許可 allow_headers=["*"], # すべてのHTTPヘッダーを許可 ) model_name = "Helsinki-NLP/opus-mt-ja-en" # トークナイザーとモデルのロード tokenizer = MarianTokenizer.from_pretrained(model_name) model = MarianMTModel.from_pretrained(model_name) @app.get("/api/translate") async def analyze_document(content : str): # トークン化 input_ids = tokenizer.encode(content, return_tensors="pt") # 翻訳の生成 output_ids = model.generate(input_ids, max_length=40, num_beams=4, early_stopping=True) # 翻訳結果をデコードして表示 translated_text = tokenizer.decode(output_ids[0], skip_special_tokens=True) return {"translate": translated_text}
以降、こちらのコードの解説を行っていきます!
クロスオリジンの設定
まず初めに、クロスオリジンの設定を行います。
app.add_middleware(
CORSMiddleware,
allow_origins=["*"], # すべてのオリジンを許可
allow_methods=["*"], # すべてのHTTPメソッドを許可
allow_headers=["*"], # すべてのHTTPヘッダーを許可
)
こちらを設定せずにAPIにリクエストを送ってもNo 'Access-Control-Allow-Origin' header is present on the requested resource.が出てしまいます。これはサーバー側が許可したオリジンやメソッドからのみリクエストを受け付ける設定となっているためです。今回はデプロイをせず、ローカルでAPIサーバーを立ち上げるのですべてのオリジンを受け入れる"*"を設定します。(もしアプリケーションをデプロイする際は、セキュリティ面で危険なので必ずオリジンの設定をフロントエンドのオリジンに設定してください。)
翻訳モデルとトークナイザーのロード
続いて、先程インストールしたHugging FaceのTransformerライブラリから翻訳モデルとトークナイザーをロードします!
model_name = "Helsinki-NLP/opus-mt-ja-en"
tokenizer = MarianTokenizer.from_pretrained(model_name)
model = MarianMTModel.from_pretrained(model_name)
今回は、Hugging Faceのモデルの中でHelsinki-NLP/opus-mt-ja-enというモデルを使用します。ここで、LLMは単語を演算処理できるようにトークン化という処理を挟みます。トークン化を行うトークナイザーには様々な種類があり、各々のLLMに対応したトークナイザーを用いてトークン化する必要があります。今回は"Helsinki-NLP/opus-mt-ja-en"に対応したトークナイザーを取得するために、MarianTokenizer.from_pretrained(model_name)を使ってトークナイザーをロードしました!
実際のAPI
最後に、実際のAPI部分について述べていきます!
@app.get("/api/translate") async def analyze_document(content : str): # トークン化 input_ids = tokenizer.encode(content, return_tensors="pt") # 翻訳の生成 output_ids = model.generate(input_ids, max_length=400, num_beams=4, early_stopping=True) # 翻訳結果をデコードして表示 translated_text = tokenizer.decode(output_ids[0], skip_special_tokens=True) return {"translate": translated_text}
まず一番上の@app.get("/api/translate")は、FastAPIのデコレーターを使ってエンドポイントのパスを設定します。この場合ですとフロントから呼び出す場合のパスは、<エンドポイントのURL>/api/translateとなります!
続いてasync def analyze_document(content : str):の部分について、こちらはただの関数名ですが、クエリパラメーターとしてcontentを受け取るように設定しています。このように指定することで、先程<エンドポイントのURL>/api/translateとしたパスの後に?content=<apiに送りたい値>をつけることで、引数を送ることができます!実際に先程のフロントエンドでapiにリクエストを送る部分では、
const requestHandler = async (url : string , translateText : string) => { const reqUrl = url + "?content=" + translateText const result = await request(reqUrl) setDisplayText(result.translate) }
エンドポイントのURLであるurlの後に"?content=" + translateTextとしてクエリパラメーターをつけ足しています!
最後に実際の翻訳部分ですが、
# トークン化 input_ids = tokenizer.encode(content, return_tensors="pt") # 翻訳の生成 output_ids = model.generate(input_ids, max_length=400, num_beams=4, early_stopping=True) # 翻訳結果をデコードして表示 translated_text = tokenizer.decode(output_ids[0], skip_special_tokens=True) return {"translate": translated_text}
ここでは送られてきたテキストであるcontentをトークン化→翻訳の生成→デコード→JSON返却の流れとなっています。先程説明しましたが、LLMは言語に対して演算処理を行うため、入出力がすべてトークンとなっています。したがって、入力前後にエンコード処理とデコード処理を挟むことで最終的な翻訳結果を生成します!
最後に、値をJSONとして返せるよう返り値をPythonの辞書形式にして処理は終了です!これで準備が整いましたので動かしてみましょう!
いざ、動かしてみる
APIを起動
APIを動かすには、コマンドラインでuvicorn main:app --reloadを実行します。ここでmainはファイル名、appはmain.pyファイル内で作成したFastAPIインスタンスの名前となっています。また、実行時のカレントディレクトリがmainファイルの場所と違う場合は、mainまでの相対パスを書いてあげる必要があります!
先程のコードを正しく実行すると、コマンドラインにUvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)といった文字が出てくるかと思います。これで、ローカルでAPIサーバーが立ち上がった状態となっており、このhttp://127.0.0.1:8000がAPIのエンドポイントとなります!
フロントを起動
続いてフロントを起動します。まずフロントのconst END_POINT = "<エンドポイントのURL>"の箇所に先程ローカルで立ち上げたAPIサーバーのエンドポイントを書き込んでおきます。あとはコマンドラインでnpm run devを実行すると、次のようなフロント部分を立ち上げることができます!
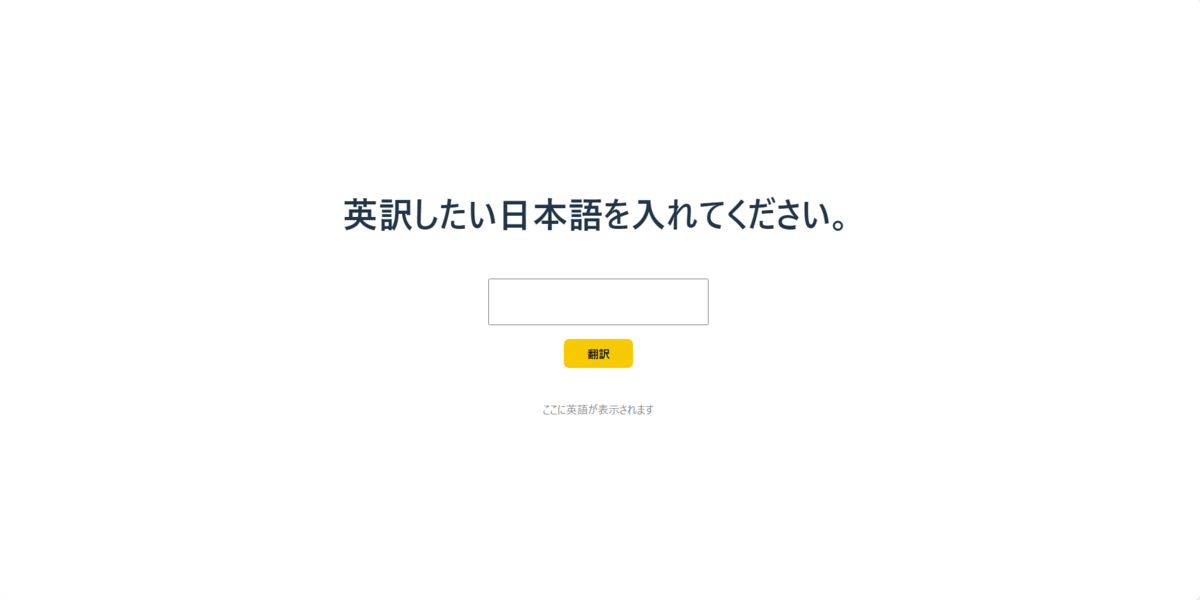 ここまでくれば完了です!実際にテキストエリアに文字を打ち込んでみると・・・
ここまでくれば完了です!実際にテキストエリアに文字を打ち込んでみると・・・
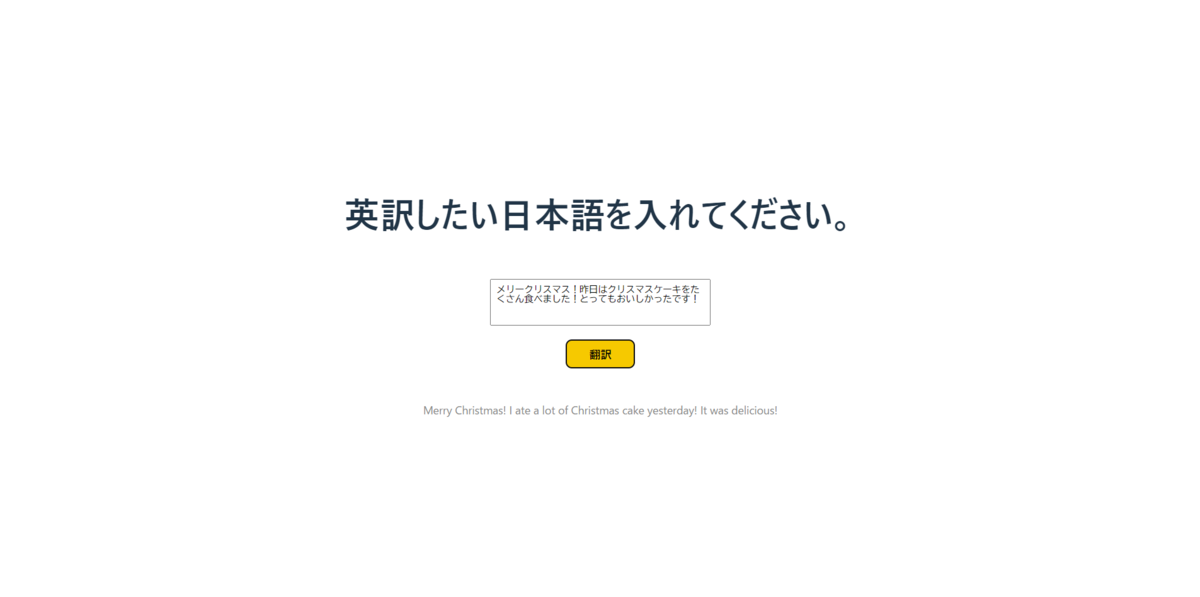 翻訳結果が返ってきました!フロントエンドからPythonで作成したバックエンドを呼び出すことができてますね😸
翻訳結果が返ってきました!フロントエンドからPythonで作成したバックエンドを呼び出すことができてますね😸
まとめ
今回はフロントエンド×バックエンド×AIを使ったローカルで動く簡単な翻訳アプリを作ってみました!それぞれ実装自体は簡素なものばかりでしたが、これまですべてをつなげた自作のアプリを作ったことがなかったので、動いたときには非常に感動しました。また、入社してからフロントエンドを担当していたこともあり、今回バックエンドの技術に触れることができたのでとても勉強になりました。みなさんもぜひ、簡単英訳アプリに挑戦してみてください!
これにて今年度のアドベントカレンダーは終了です!今回初めてアドベントカレンダーに参加しましたが、たくさんの素晴らしい記事が集まり、技術への情熱や知見だけでなく、社内の雰囲気を社外の方にも共有できる場となりました。来年もChallenge&Changeの精神をもってドンドン成長し、たくさんの記事をお届けできれば良いなと思います。 最後になりましたが、ここまで読んでくださった皆様、そしてアドベントカレンダーに記事を投稿してくださった皆様、本当にありがとうございました!それでは残り少ないですが、良いお年を👋
おわりに
KENTEMでは、様々な拠点でエンジニアを大募集しています!
建設×ITにご興味頂いた方は、是非下記のリンクからご応募ください。
recruit.kentem.jp
career.kentem.jp