
こんにちは。皆さんはデータ構造、お好きですか?今回は木構造の内容です。二分木、B木などが有名ですね。
今回は木構造の表現方法を紹介したいと思います。
木構造の定義
まずは木構造の定義を確認しておきます。辞書を引いてみると、このようにあります。
データ構造の一種。一つの要素が複数の要素への分岐情報を持つ階層的な構造。要素の連結状態が枝分かれした木のように見えることからいう。木構造。(広辞苑 第六版)
文字だけではイメージしにくいです。サクッと図で確認しましょう。
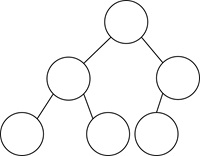
こんなのですね。 ちなみに、数学的には「閉路を持たない連結なグラフ」を指します。閉路はループのことで、連結はグラフが複数に分かれていないことですね。木であるための条件は他にもありますが、そのうち1つを満たせば他のすべての条件も満たされるというような関係になっています。グラフの中での特殊なケースということです。
二分木
簡単な木構造として先に二分木を紹介します。 すべてのノードの子の数が高々2である木のことです。 この二分木ですが、実装するときにはどのような方法があるでしょうか。例えば次のような実装があります。図ではイメージを示しています。
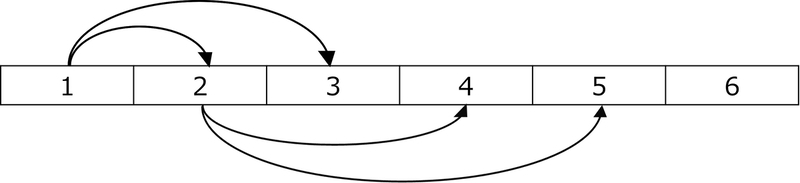
配列で管理する
各ノードが配列に格納される。
自身の格納インデックスをnとすると、左の子は2n、右の子は2n+1のインデックスに存在
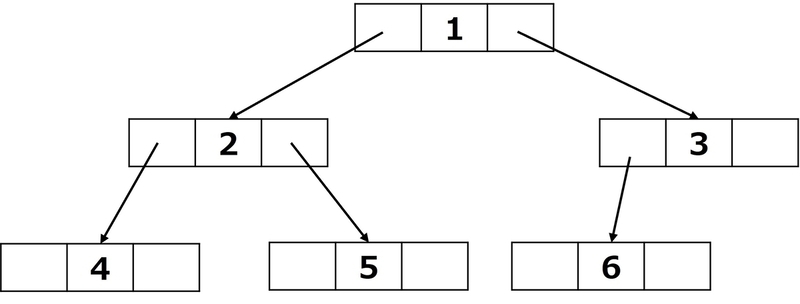
ポインタで管理する
配列のような順序のあるデータ構造を取らず、各ノードが左の子と右の子のポインタを保持する
実装によってノードの追加や削除の計算量に違いが出てきます。 例えば配列で管理するとすべてのノードに定数時間でアクセスすることができますが、ポインタで管理すると辿っていく必要があり、最大でノード数分の計算量が発生します。
多分木
次はこの二分木を子の数について一般化して、子が任意の数になるn分木(多分木)について考えてみます。 単純な配列で実装しようとすると、子の数の上限を設定しないとうまくいきません。
ここで今回紹介したかった木です。多分木の表現方法の一つで、二重連鎖木というものです。
二重連鎖木はdoubly chained treeやleft-child right-sibling representationなどという言われ方もされ、こちらの方がなじみがあるという場合もあるようです。
この二重連鎖木では各ノードが自身の最初の子と次の兄弟だけ把握している構造を持ちます。二分木を二重連鎖木で表現するとこのようになります。
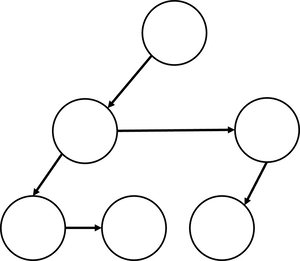
二分木だとそれほど変化がないので利点がわかりにくいですね。では次のようなツリーで見てみましょう。
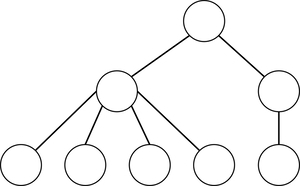
これを二重連鎖木で表現するとこうなります。
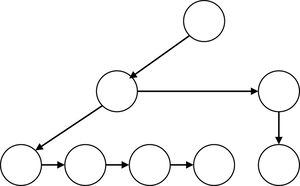
各ノードが持つ情報が最初の子と次の兄弟の情報だけなので皆同じ形の情報しか持たなくて良く、実装が簡単になります。
もしそれぞれのノードが自身の子を配列として保持すると、上の例では根のノードは子の配列の長さが2であり、一方で根の最初の子が持つ配列は長さが4で形に違いが発生してしまいます。これでは実装がやや煩雑になります。
それでは次に具体的な表現や計算量の比較をしてみましょう。
各ノードは一意なidを持っているものとします。 二重連鎖木ではポインタが必要になりますが、私が使っているのはJavaScriptなので連想配列で代用します。 また、子を配列で保持する表現を"入れ子構造"と呼ぶことにします。
二重連鎖木(連想配列)
idをキーとする連想配列でツリーを保持します。 先ほどの状態から情報を拡張して、各ノードは自身の親、最初の子、前後の兄弟のidを持ちます。
TypeScriptの型としては{[id:string]:Node}で、これを配列として持つので{[id:string]:Node}[]です。
[ "1":{ parent:undefined, firstChild:"2", nextSibling:undefined, previousSibling:undefined }, "2":{ parent:"1", firstChild:"4", nextSibling:"3", previousSibling:undefined }, "3":{ parent:"1", firstChild:"6", nextSibling:undefined, previousSibling:"2" }, "4":{ parent:"2", firstChild:undefined, nextSibling:"5", previousSibling:undefined }, "5":{ parent:"2", firstChild:undefined, nextSibling:undefined, previousSibling:"4" }, "6":{ parent:"3", firstChild:undefined, nextSibling:undefined, previousSibling:undefined } ]
入れ子の構造
格納されている順番がそのままノードの順番になります。
[ { id:"1", children:[ { id:"2", children:[ { id:"4", children:[] }, { id:"5", children[] } ] }, { id:"3", children:[ { id:"6", children:[] } ] } ] } ]
どちらがお好みでしょうか。
操作の計算量の比較
次にこの2つの構造に対して、以下の操作を行うことを考えます。
- idによるノードの検索
- ノードの追加
- ノードの削除
- ノードの並びかえ
これらの操作をするとき、計算量にどのような差があるでしょうか。
ノード数をnとして比較を行っていきます。
idによるノード検索
- 入れ子の場合 :
O(n)
親から順に一つ一つノードのidを見ていく必要があるためノード数分かかりますね。
- 連想配列の場合 :
O(1)
idは連想配列のキーなので直接アクセスできます。
ノードの追加
idを指定してそのノードの兄弟、または子としてノードを追加します。兄弟や子がすでに存在する場合、末尾に追加します。
- 入れ子の場合 :
O(n)
指定されたidを持つノードの検索にn、最後の兄弟または子まで たどるのにはlength-1でアクセスして追加すれば良いです。
- 連想配列の場合 :
O(n)
指定されたノードを検索するのは定数時間で済みますが、次の兄弟をたどっていく必要があり、最悪の場合ノード数分だけかかってしまいます。
ただし、連想配列の最悪の場合はノードが全て兄弟要素として並んでいるときであるため、実際に使う時のことを考えると入れ子の場合の方が時間は長くなりがちだと思われます。
ノードの削除
指定したidのノードを削除します。
- 入れ子の場合 :
O(n)
ノードの検索にn、配列から要素を削除するのに、nかかります。それぞれ独立した操作なので定数倍で済みます。
- 連想配列の場合 :
O(1)
ノードの検索は定数時間、配列から要素を削除するには前後の接続を繋ぎ変えるだけで良いため、定数時間で済みます。
ノードの並び替え
移動するidと挿入先のidを指定して後ろに挿入する操作を行います。
- 入れ子の場合 :
O(n)
検索に2n、配列になっているため、挿入にも最大nかかります。
- 連想配列の場合 :
O(1)
検索が定数時間で済み、挿入も元の位置と挿入先で前後の接続を変更するだけなので定数時間で行うことができます。
計算量の比較は以上です。削除や並び替えで差が出てきましたね。 私としては計算量だけでなく、全探索をするときの実装も連想配列の方が楽だと思っています。
また、探索をするときにスタックに入れていくことを考えると、入れ子の場合は子の配列を入れる必要がありそうで、スタックに入るものの形が一定でないことが気になります。 一方連想配列では二分木のようにして扱えるので次のノードか最初の子を入れていけば良いだけです。スタックには常にノード単体が積まれているので安心です。
まとめ
今回は二重連鎖木という表現方法を紹介しました。多分木の実装の方法として有用なものだと思います。 データ構造によって実装の難易度や計算量が変わるので新しく実装するときの検討は重要ですね。では、良いデータ構造ライフを。
おわりに
KENTEMでは、様々な拠点でエンジニアを大募集しています!
建設×ITにご興味頂いた方は、是非下記のリンクからご応募ください。
recruit.kentem.jp
career.kentem.jp