Web アプリケーションなどで日々蓄積されるログデータ、その他ちょっとしたデータを可視化・分析してみたくなったことは無いでしょうか?
データを可視化する際にぱっと思い浮かぶのは Excel だったりするでしょうが、データを Excel に貼って範囲指定してグラフを挿入して...と、非常に煩わしいものです。
データ サイエンスが注目される昨今、世の中には数多くのデータ分析・可視化ツールがありますが、ちょっとかじってみるにも、なかなか有償のものには手が出しづらく、使い方から調べるのも大変で最初の一歩が出ないことも多々あるかと思います。
そこで、Elastic 社からダウンロード版として入手も可能な、Elasticsearch というデータ検索/分析エンジンと Kibana というデータ分析・可視化ツールを使い、C# の簡単なプログラムにてデータを投入するサンプルコードを作ってみました。
Elasticsearch + Kibana の動かし方や、Kibana でのグラフの作り方も簡単に紹介します。
データの可視化や分析に少し興味のある C# プログラマーの皆さん、お時間ある時にちょこっと手を動かして実践してみましょう。
- Elasticsearch + Kibana
- データ分析用のサンプル データの用意
- C# コンソールアプリでの CSV データ読み込み・投入
- Kibana での投入データの確認と可視化の準備
- ダッシュボードを作成してデータを可視化する
- おわりに
Elasticsearch + Kibana
Elasticsearch と Kibana の特徴を、今はやりの Copilot に聞いてみました。
| Elasticsearch | Kibana | |
|---|---|---|
| 特徴 | ・Elastic 社が開発している全文検索エンジン ・ログ解析や検索、リアルタイムのデータ解析などが行える ・他のツールと組み合わせることで、分析結果のグラフ表示やログの集約がしやすくなる ・RDB で言うところのデータベースを横断しての検索が可能 |
・Elasticsearch 内のデータを様々な形式で可視化できるツール ・GUI ベースで操作が可能で、データのグラフ化や分析に強いツールと言える |
| ダウンロード URL | https://www.elastic.co/jp/downloads/elasticsearch | https://www.elastic.co/jp/downloads/kibana |
概要が分かったところで、さっそくダウンロードして使っていきましょう。
ダウンロードとファイル展開
ファイルのダウンロードは上記 URL にて行います。
これ以降の説明は Windows 版での説明になりますので、ダウンロード サイトを開いた先の [Windows] ボタンをクリックします。
.zip ファイルがダウンロードされますので、ファイル展開前に、エクスプローラーにてそれぞれのファイルのプロパティを開き、セキュリティの [☑許可する] をチェックして [OK] しておきます。

Elasticsearch はすぐですが、Kibana はファイル数が非常に多く、.zip ファイルをダブル クリックして中身を見るだけでも数分程度かかる可能性がありますので、右クリック メニューの [すべて展開...] を利用し、階層の浅い、例えば C:\📂Elastic 等のフォルダー配下に展開するのが良いでしょう。
以降は、次のような階層にそれぞれを展開したとして説明していきます。
C:\📂Elastic
┣ 📂Elasticsearch
┗ 📂Kibana
設定ファイルの修正
Elasticsearch、Kibana を起動する前に、少しだけ設定ファイルの修正を行います。
それぞれ以下のフォルダー配下のファイルを一度バックアップを取ったうえで編集し、以下の箇所を追記します。
※以下の「:」は省略を意味します。
[ C:\📂Elastic\📂Elasticsearch\📂config\📄elasticsearch.yml ]
: xpack.security.enabled: false
※ ↑ ファイルの末尾に1行追記
[ C:\📂Elastic\📂Kibana\📂config\📄kibana.yml ]
: # Specifies locale to be used for all localizable strings, dates and number formats. # Supported languages are the following: English (default) "en", Chinese "zh-CN", Japanese "ja-JP", French "fr-FR". #i18n.locale: "en" i18n.locale: "ja-JP" :
上記の elasticsearch.yml の設定は http での応答を許可するもので、セキュリティ上推奨されない設定ですが、これにより http 通信での localhost:9200 ポートを使ったデータ投入ができる様になり、Kibana 起動時の登録トークンやパスワード入力といった手順・説明も不要となりますので、この設定を使用することにします。
kibana.yml の設定は、上のコメントにもある通り Kibana の UI を日本語に切り替えるための設定です。
これで起動する準備ができましたが、初回起動時のみ次に示す作業が必要となります。
起動方法と初回起動時の設定等
起動はそれぞれ以下のバッチファイルを利用します。
上述の通り、初回起動時は次項に示すような形で起動してください。
- C:\📂Elastic\📂Elasticsearch\📂bin\📄elasticsearch.bat
- C:\📂Elastic\📂Kibana\📂bin\📄kibana.bat
※次回以降の起動用に、適当な場所にショートカットを作っておくと良いでしょう。
初回起動と起動確認
初回起動はそれぞれ少し時間がかかります。
Elasticsearch の初回起動と確認
elasticsearch.bat をダブルクリックし、数分待ちます。
コマンドプロンプトの画面の動きが無くなり、以下の様な表示になると起動完了です。
:
[2024-05-02T16:21:44,892][INFO ][o.e.x.i.a.TransportPutLifecycleAction] [自分の PC 名] adding index lifecycle policy [.fleet-file-fromhost-data-ilm-policy]
[2024-05-02T16:21:45,362][INFO ][o.e.h.n.s.HealthNodeTaskExecutor] [自分の PC 名] Node [{自分の PC 名}{vIJCn8rrTGydk6HRybRc6Q}] is selected as the current health node.
[2024-05-02T16:21:45,941][INFO ][o.e.l.ClusterStateLicenseService] [自分の PC 名] license [4f12525f-943f-43d2-9e94-6887be78766a] mode [basic] - valid
ブラウザーにて以下の URL にアクセスし、この様な JSON が表示されれば OK です。
⇒ http://localhost:9200/
{ "name": "自分の PC 名", "cluster_name": "elasticsearch", "cluster_uuid": "tuMWePxQQO6Iq0aaXQr_SA", "version": { "number": "8.12.2", "build_flavor": "default", "build_type": "zip", "build_hash": "48a287ab9497e852de30327444b0809e55d46466", "build_date": "2024-02-19T10:04:32.774273190Z", "build_snapshot": false, "lucene_version": "9.9.2", "minimum_wire_compatibility_version": "7.17.0", "minimum_index_compatibility_version": "7.0.0" }, "tagline": "You Know, for Search" }
Kibana の初回起動と確認
kibana.bat をダブルクリックし、しばらく待ちます。
コマンドプロンプトに以下の表示がされて動きが止まりますが、そこから数分待つ必要があります。
: [2024-05-02T16:31:02.212+09:00][INFO ][root] Kibana is starting [2024-05-02T16:31:02.365+09:00][INFO ][node] Kibana process configured with roles: [background_tasks, ui]
しばらくして、
: [2024-05-02T16:39:31.239+09:00][INFO ][status] Kibana is now available (was degraded) :
といった表示が見えれば、Kibana が起動可能になっています。
ブラウザーにて以下の URL にアクセスすると、Elastic の読み込み中... の後、以下の様なページが表示されます。
⇒ http://localhost:5601/
[統合の追加] は色んなサービスとの接続をするためのメニューが出てきます。
[独りで閲覧] というのは何だか日本語訳がおかしい気がしますが、こちらを選択します。
画面の中に以下の様な表示が出ます。

時間があれば、[サンプルデータを試す] から [> 他のサンプルデータセット] をクリックすると、3つほどのサンプル データとグラフを追加する画面が表示されますので、そちらで [データ追加] して、色々なグラフを見てみると良いでしょう。
また、画面の右下に以下の様な吹き出しが表示されますが、こちらは閉じてしまって結構です。
次回以降の起動と停止
次回以降は、Elasticsearch の方からバッチファイルをダブルクリックするだけです。
停止する際は、Kibana のコマンドプロントから、ctrl + c キーにて停止します。
さて、それでは次の分析用のサンプル データの準備に入りましょう。
データ分析用のサンプル データの用意
分析のためのサンプルデータとして、国土交通省 - 気象庁 の以下のサイトから CSV ファイルをダウンロードし、それを Elasticsearch に投入することにします。
⇒ 気象庁|過去の気象データ・ダウンロード (jma.go.jp)
KENTEM 本社は富士山のふもとの富士市にありますので、この説明では静岡県のいくつかの地域から気温や天気のデータをダウンロードすることにします。
気温・天気データのダウンロード
上記サイトにアクセスすると、日本の地図の画面が表示されますので、[静岡] 県を選択し、[地点を選ぶ] から以下の様に [富士山], [富士], [静岡], [浜松], [御前崎], [石廊崎] を選択します。
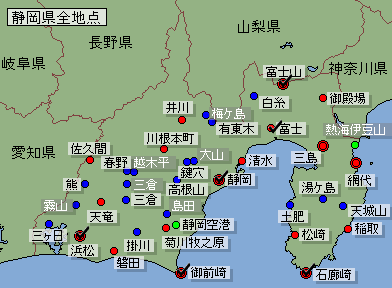
次は [項目を選ぶ] にて、以下の様に選択。[気温] は3つの値と、平年値も取得しておきましょうか。
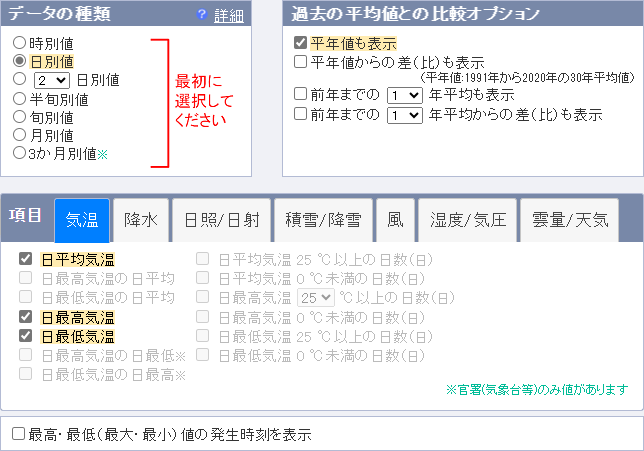
ついでに、気温とは別の [雲量/天気] から、昼の [天気概況] も選択します。

少々選択項目が多いため、[期間を選ぶ] では、昨年度 (2023) の半年を選択。
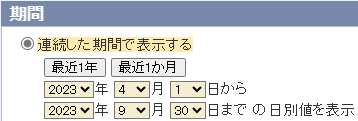
次の [表示オプションを選ぶ] では、"均質番号" や "品質情報" といった項目は必要ないので、以下の様に選択。

これで右上のゲージが目一杯近くになりますので、[CSVファイルをダウンロード] をクリック。
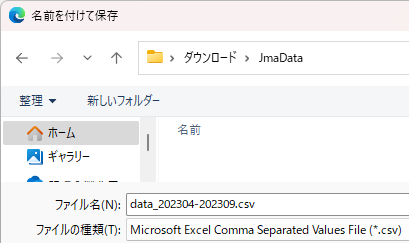
以下は Edge の画面ですが、[名前を付けて保存...] にて、ダウンロード先は、📂ダウンロード 配下に新しいフォルダー 📂JmaData を作り、そこに例えば「data_202304-202309.csv」といった名前で保存します。
再度、[期間を選ぶ] にて、今度は 2023/10/01~2024/03/31 として再度ダウンロードし、「data_202310-202403.csv」といった名前で保存します。
📂ダウンロード
┗📂JmaData
┣📄data_202304-202309.csv
┗📄data_202310-202403.csv
ダウンロードしたファイルの確認
ダウンロードした CSV ファイルを Excel で開くと以下の様なデータになっていることが確認できます。

さすが日本一の霊峰、富士山は寒いですねぇ。それはさておき、天気概況については、富士市などのローカル地域 (?) はデータが無く、選んだ6地点では静岡だけが値を持っており、他は空欄となっているデータであることが確認できます。
このことを考慮しつつ、この CSV データを Elasticsearch に投入していきます。
C# コンソールアプリでの CSV データ読み込み・投入
ではここからが本番です。
このセクションでは、Visual Studio 2022 を使用し、ASP.NET Core 8.0 のコンソールアプリにて、以下のコードを書いて(コピペして)行きます。
プロジェクトの作成
Visual Studio を起動し、スタート ウィンドウ右側の [開始する] から [新しいプロジェクトの作成] をクリックします。

コンソールアプリ (.NET Framework ではない上の方) を選択して次へ。
プロジェクト名をそれなりに入力して次へ。

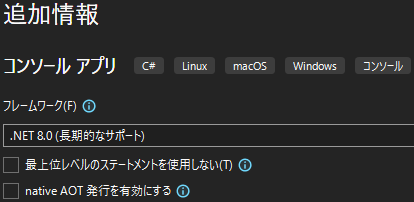
.NET 8.0 を選んで、最上位レベルのステートメントを使用する形(チェック無し)で [作成] をクリックします。
以下の様にシンプルなコードのコンソールアプリが作られます。

ここに以下のクラスや処理を書いて行きます。
- ① データ投入処理と画面表示
- ② データ投入用のモデル
- ③ CSV の読み込みクラス
コードを書いて行く前のもう一つの準備として、Nuget パッケージのインストールを先に行います。
Nuget パッケージのインストール
データ投入を行う際に使用する Elasticsearch の Nuget パッケージと、CSV ファイルが Shift-JIS になっているので、その Encoding をするためのパッケージを追加します。
ソリューションの右クリック メニューから ![]() を選択し、以下の2つをインストールします。
を選択し、以下の2つをインストールします。

プログラムの実装
① データ投入処理と画面表示
この後で説明する ② のモデルと ③ のクラスを用い、Elasticsearch にデータを投入しつつ、個々のデータを画面表示する処理です。
2か所の「//★」マークの行は一旦コメントアウトした状態にします。
using Elastic.Clients.Elasticsearch; using System.Collections; using System.Text; // インデックス名(小文字)と読み込む CSV ファイル string indexName = nameof(JmaData).ToLower(); string folderPath = Path.Combine(Environment.GetFolderPath(Environment.SpecialFolder.UserProfile), "Downloads", "JmaData"); string[] csvFiles = Directory.GetFiles(folderPath, "*.csv"); // ElasticsearchClient のインスタンス生成 //var client = new ElasticsearchClient(); //★ // .csv ファイルの読み込みとデータ投入(インデックスの作成) var rowCount = 0; var dataCount = 0; foreach (var csv in csvFiles) { Console.WriteLine($"[{csv}]"); foreach (var row in new CsvReader(csv)) { rowCount++; foreach (var item in row) { dataCount++; Console.WriteLine($"{item.Id}\t{item.DateTime}\t{item.Location}\t{item.DataType}\t{item.Value}\t{item.Data}"); //await client.IndexAsync(item, (IndexName)indexName); //★ } } } Console.WriteLine($"\n行数:{rowCount} / 有効列数:{dataCount / rowCount} / データ数:{dataCount}"); Console.ReadKey();
「//★」マークの処理については以下のサイトに簡単な説明があります。
⇒ Getting started | Elasticsearch .NET Client 8.9| Elastic
※データ投入先が自分の PC でない場合は、ElasticsearchClient("http://○○:9200") といった書き方で行き先を変えることができます。
※IndexAsync は、公式の説明では IndexAsync(doc, "my_index") と書かれていますが、(IndexName) でキャストしないとエラーになります。
※大量データを投入する場合は BulkAsync(...) などの一括処理も可能ですが、ここでは説明を割愛します。
② データ投入用のモデル
上記 Excel で確認した内容の CSV ファイルを Elasticsearch に投入するためのモデルを作成します。
// インデックスの型 (※Id は年月日時 + Hash 値により、一意の値になる様にする) class JmaData { public long Id => long.Parse(DateTime.ToString("yyMMddHH00000000000")) + (uint)(Location + DataType).GetHashCode(); public DateTime DateTime { get; set; } public string? Location { get; set; } public string? DataType { get; set; } public double Value { get; set; } public string? Data { get; set; } }
ここで「インデックスの型」と表記していますが、Elasticsearch では、データの種類ごとに、データベースのテーブルに相当する「インデックス」にデータを登録していきます。
CSV ファイルの気温や天気概況の値1つに対して1つのモデルのインスタンスを生成し、その値と日付や地区・データの種類を以下に示すプロパティに代入つつ、データ投入する様にします。
各プロパティは以下の役割で使用します。
| プロパティ名 | 役割 |
|---|---|
| Id | データ1つ1つを識別する一意の ID になる様な値を設定します。 データを再投入したり、重複したデータを投入したりした際に、データが増えてしまわない様な ID にします。 |
| DateTime | Kibana にてグラフ化する際に、時系列として扱うデータとして用意します。 |
| Location | このプログラムでは、"富士" などの地区名を入れます。 |
| DataType | Excel の 4, 5 行目の "平均気温 (℃)" や "平年値 (℃)" といったデータの種類を表す値を入れます。 |
| Value | 数値データ(ここでは気温)を入れます。 |
| Data | 文字列データ(ここでは天気概況)を入れます。 |
この様に、データ分析では、元のデータを分析しやすいデータ形式(モデル)に変換しつつデータ投入することが肝要となります。
③ CSV の読み込みクラス
少々長く、これがこのプログラム最大のコードになってしまいますが、CSV ファイルを読み込み、上記データ投入用のモデルとして foreach にて取り出す仕組みです。
※ここで説明する CSV ファイルとは異なる形式のデータを取り込む際には、上部の const 値を修正してください。
※最近の C# のコードに準じた表記をなるべく使い、可読性・処理効率よりコードの短さを優先してしまいました。変な所はご勘弁を。
// CSV 読み込み・データ取得クラス class CsvReader : IEnumerator<JmaData[]>, IEnumerable<JmaData[]> { private const int DATA_START_ROW = 5; // データの開始列番号 (0 スタート) private const int DATA_START_COL = 1; // 〃 行番号 ( 〃 ) private const int DATE_TIME_COL = 0; // 日時を取得する列番号 private const int LOCATIONS_START_ROW = 2; // 観測地点を取得する行番号 private const bool LOCATIONS_MULTI_ROWS = false; // 観測地点を2行から取得するかどうか private const int DATATYPES_START_ROW = 3; // データ種別を取得する行番号 private const bool DATATYPES_MULTI_ROWS = true; // データ種別を2行から取得するかどうか private readonly List<List<string>> _csvData = []; private readonly List<string> _locations = []; private readonly List<string> _dataTypes = []; private int _currentRow = DATA_START_ROW - 1; public CsvReader(string filePath) { using var sr = new StreamReader(filePath, CodePagesEncodingProvider.Instance.GetEncoding("Shift_JIS")!); while (!sr.EndOfStream) { string? line = sr.ReadLine(); List<string> rowData = new(string.IsNullOrEmpty(line) ? [] : line.Split(',')); _csvData.Add(rowData); } GetHeader(_locations, LOCATIONS_START_ROW, LOCATIONS_MULTI_ROWS); GetHeader(_dataTypes, DATATYPES_START_ROW, DATATYPES_MULTI_ROWS); } private void GetHeader(List<string> list, int startRow, bool multiRows) => list.AddRange(_csvData[startRow].Skip(DATA_START_COL) .Select((x, i) => x + (multiRows ? $" {_csvData[startRow + 1][DATA_START_COL + i]}" : ""))); public JmaData[] Current { get => _csvData[_currentRow].Skip(DATA_START_COL).Select((x, i) => { bool isValue = double.TryParse(x, out double value); return string.IsNullOrEmpty(x) ? null : new JmaData() { DateTime = DateTime.Parse(_csvData[_currentRow][DATE_TIME_COL]), Location = _locations[i], DataType = _dataTypes[i], Value = isValue ? value : 0, Data = isValue ? "" : x }; }).Where(x => x != null).ToArray()!; } object IEnumerator.Current => Current; public bool MoveNext() => ++_currentRow < _csvData.Count; public void Reset() => _currentRow = DATA_START_ROW - 1; public void Dispose() { } public IEnumerator<JmaData[]> GetEnumerator() => this; IEnumerator IEnumerable.GetEnumerator() => this; }
まずは実行(データ投入無し)
さて、まずは「//★」マークの行はコメントのまま実行してみます。
以下の様な形で CSV ファイルの内容が表示されたら OK です。
: 2403310000666584435 2024/03/31 0:00:00 静岡 最高気温(℃) 平年値(℃) 17.4 2403310002701417650 2024/03/31 0:00:00 静岡 最低気温(℃) 12.1 2403310000185535860 2024/03/31 0:00:00 静岡 最低気温(℃) 平年値(℃) 7.9 2403310001496897356 2024/03/31 0:00:00 静岡 天気概況(昼:06時~18時) 0 晴後一時曇 2403310001328592737 2024/03/31 0:00:00 浜松 平均気温(℃) 17.9 2403310002775634130 2024/03/31 0:00:00 浜松 平均気温(℃) 平年値(℃) 12.4 2403310000575520410 2024/03/31 0:00:00 浜松 最高気温(℃) 25.2 2403310004083110107 2024/03/31 0:00:00 浜松 最高気温(℃) 平年値(℃) 17.1 2403310004030885921 2024/03/31 0:00:00 浜松 最低気温(℃) 11.9 2403310000313284790 2024/03/31 0:00:00 浜松 最低気温(℃) 平年値(℃) 7.8 2403310001355235029 2024/03/31 0:00:00 石廊崎 平均気温(℃) 17.6 2403310003598150539 2024/03/31 0:00:00 石廊崎 平均気温(℃) 平年値(℃) 12.7 2403310002071747958 2024/03/31 0:00:00 石廊崎 最高気温(℃) 20.7 2403310001489355003 2024/03/31 0:00:00 石廊崎 最高気温(℃) 平年値(℃) 15.7 2403310002056454782 2024/03/31 0:00:00 石廊崎 最低気温(℃) 15.8 2403310002081587866 2024/03/31 0:00:00 石廊崎 最低気温(℃) 平年値(℃) 9.7 2403310003146927211 2024/03/31 0:00:00 御前崎 平均気温(℃) 17 2403310003807383829 2024/03/31 0:00:00 御前崎 平均気温(℃) 平年値(℃) 12.4 2403310000222483557 2024/03/31 0:00:00 御前崎 最高気温(℃) 20 2403310000160125005 2024/03/31 0:00:00 御前崎 最高気温(℃) 平年値(℃) 16.1 2403310001510697290 2024/03/31 0:00:00 御前崎 最低気温(℃) 14.6 2403310001790380408 2024/03/31 0:00:00 御前崎 最低気温(℃) 平年値(℃) 8.4 行数:366 / 有効列数:37 / データ数:13542 C:\KS\Elasticsearch\vs_proj\CSVUploader\CSVUploader\bin\Debug\net8.0\CSVUploader.exe (プロセス 37844) は、コード 0 で終 了しました。 デバッグが停止したときに自動的にコンソールを閉じるには、[ツール] -> [オプション] -> [デバッグ] -> [デバッグの停止時に自 動的にコンソールを閉じる] を有効にします。 このウィンドウを閉じるには、任意のキーを押してください...
データ投入
それでは、実際にデータ投入をしてみましょう。
Elasticsearch.bat と Kibana.bat が実行されていることを確認のうえ、「//★」行のコメントを外して実行します。
少々時間がかかりますが、上記と同じ表示となって処理が終わるのを待ちます。
Kibana での投入データの確認と可視化の準備
それではブラウザーにて Kibana の画面を表示し、投入したデータ(インデックス)を確認します。
インデックスの確認
インデックスは、画面左上の [ ] アイコンをクリックして、何故か一番下にある赤枠の [Stack Management] をクリックして開きます。
] アイコンをクリックして、何故か一番下にある赤枠の [Stack Management] をクリックして開きます。
(※後ほど [Dashboards] も使うので覚えておきましょう。)
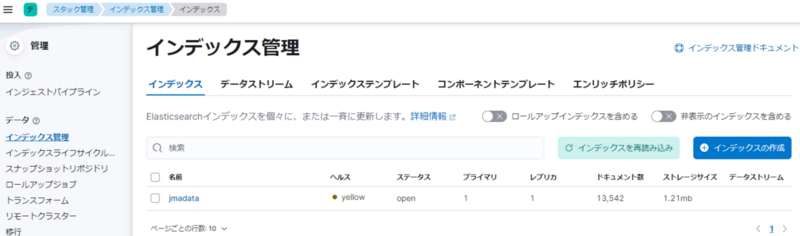
ここに、先ほど投入したデータが「jmadata」というインデックス名で表示されているかと思います。
ここで「ドキュメント数」はコンソールの「データ数」で表示された 13,542 と同じ数になるはずですが、そうなるには数分程度待つ必要があります。
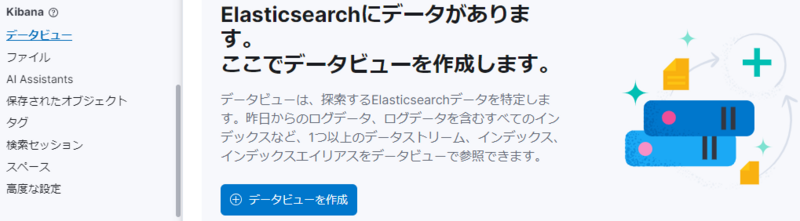
データビューの作成
インデックスができたら、すぐにグラフを作れる訳ではありません。
その前に「データビュー」というものを作る必要があります。
[データビューを作成] をクリックして、以下の様に入力して [データビューを Kibana に保存] します。
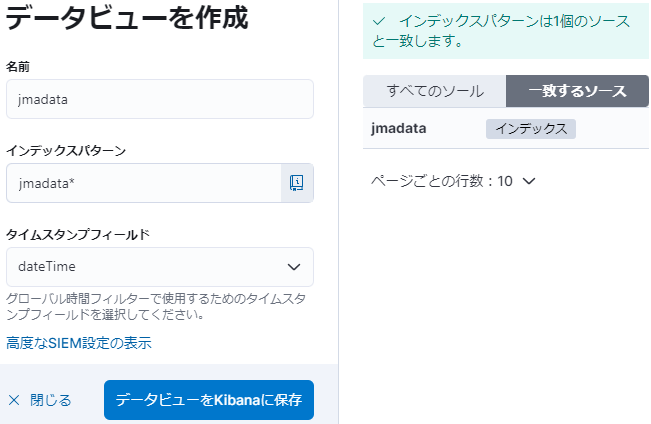
以下の様なデータビューが表示されます。
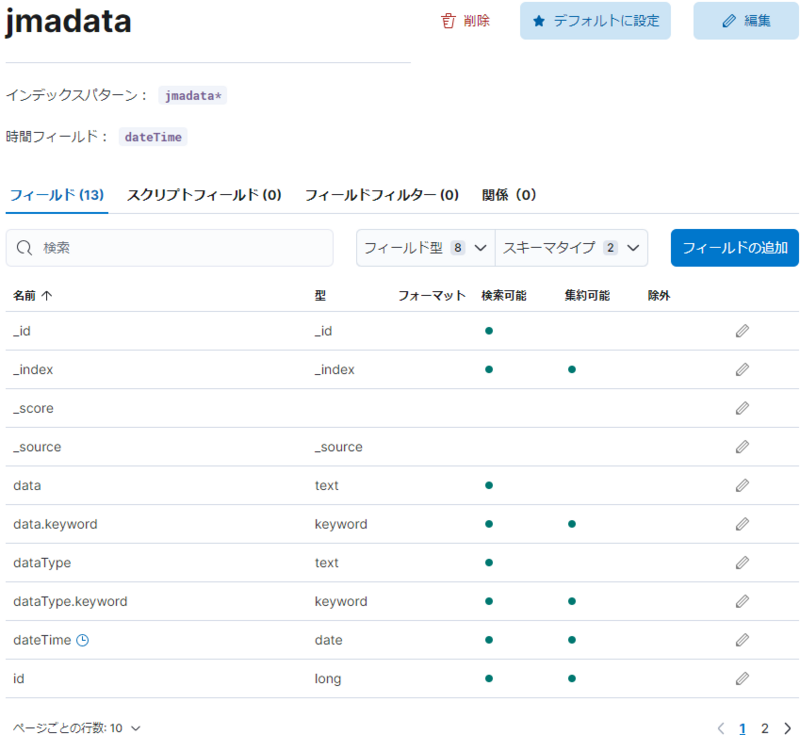
1つ画面を戻ると、「jmadata」のデータビューが一覧登録されていることが分かります。
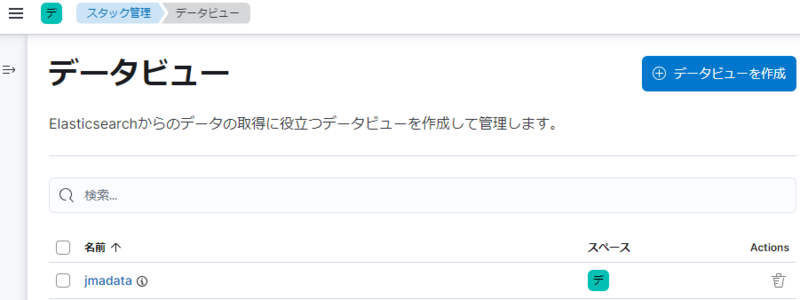
ここで何故データビューが必要なのか? と思われるかもしれませんが、データビューは以下の様な重要な役割を持っています。
- 複数のインデックスを1まとめにする
- スクリプト (Java など) にてフィールドの値を加工して別のフィールドに格納する
- 権限や役割を割り当てる
ダッシュボードを作成してデータを可視化する
さて、いよいよデータの可視化に入ります。
[ダッシュボードの作成] → [ビジュアライゼーションを作成] をクリックします。

以下の様な画面に切り替わります。
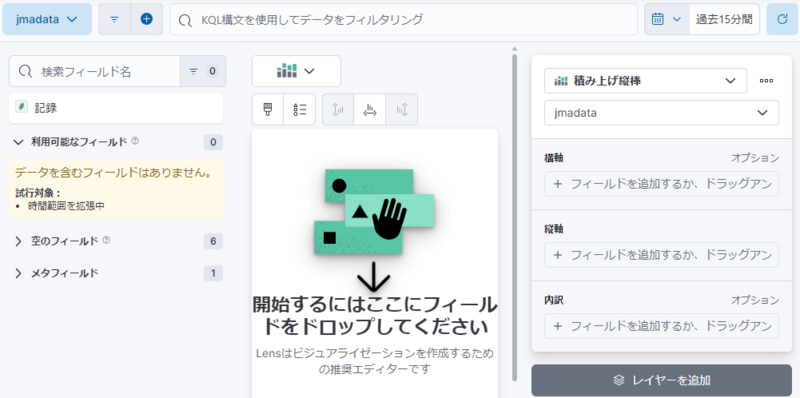
気温のグラフ化
まずは気温をグラフ化してみましょう。グラフは [折れ線] に切り替えます。
右ペインの [横軸] をクリックして、[日付ヒストグラム] を選ぶと、フィールドは「dateTime」が選択されます。
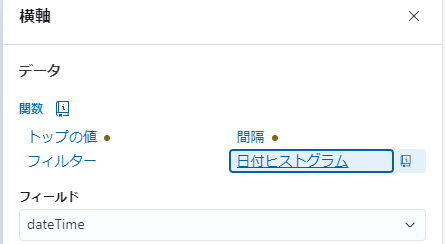
次は [横軸] を以下の様にします。

最後に [内訳] を設定します。データの中には「天気概況」の value = 0 のデータも含まれるため、「その他」としてのグループ化を OFF にすると良いでしょう。

日付の範囲もデータ投入範囲に合わせて変更することをお忘れなく。

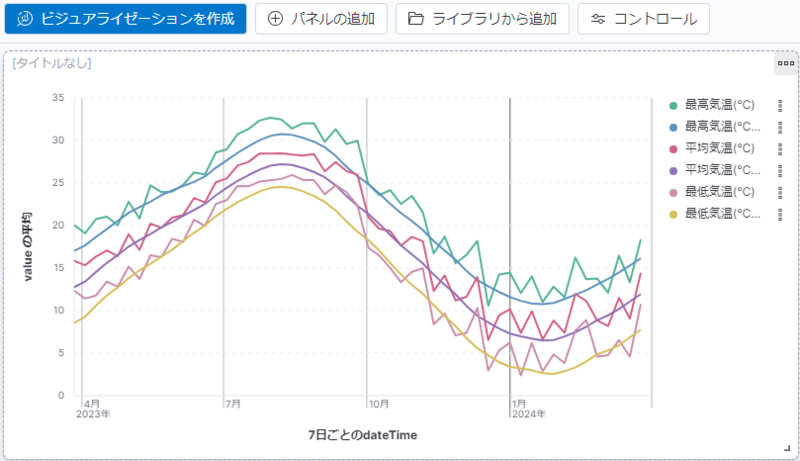
以下の様なグラフが表示されたでしょうか。
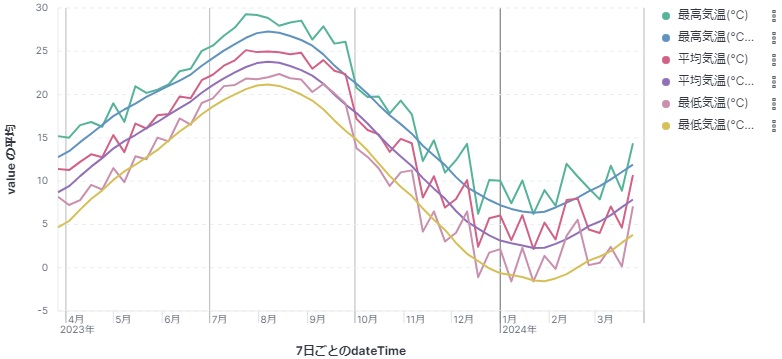
ここで夏の最高気温が 30 ℃ 行かないのか? と思った方は鋭い!
このグラフは "富士山" を含む6地区の平均値のグラフになっているのがその理由です。
データを可視化する際には、出てきたデータが妥当なものになっているかを検証することも必要になります。
"富士山" を除くには、[縦軸] の [高度な設定] より、[フィルタリング条件] を以下の様に設定します。
※「=」の代わりに「:」、除外は「not」を付けます。「and」や「or」、括弧「()」を使っての複数指定、数値は不等号も使用可能です。
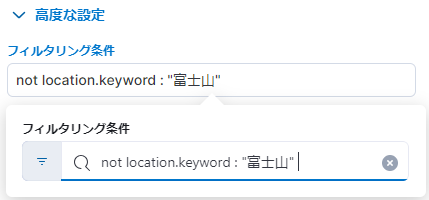
夏の最高気温が 32.6 ℃ くらいに変わったでしょうか?
この様にしてフィルタリング条件を指定しながら必要なデータの抽出をしていきます。
最後は画面右上の ![]() をクリックすると、作成したグラフが保存されます。
をクリックすると、作成したグラフが保存されます。
このグラフで問題ないようなら、さらに画面の右上のボタンでダッシュボードを [保存] します。
![]()
ダッシュボードに名前を付けて保存します。
天気のグラフ化
もう一つ、「天気」をグラフ化してみましょう。
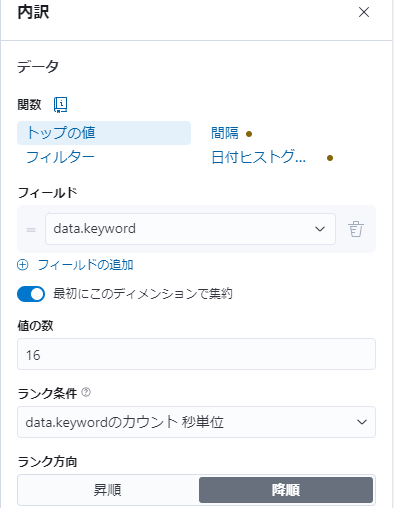
[縦軸] は [最低間隔] を1ヵ月 (1 M) にします。

[横軸] の関数は [カウント]、フィールドは「data.keyword」、フィルタリング条件は "天気概況..." にします。

[内訳] のフィールドは同様に「data.keyword」、値の数は... いったい幾つ天気があるんだ? 細かすぎだろ! と思いつつ「16」あたりにしておきましょうか。
天気のグラフが出来上がりました。
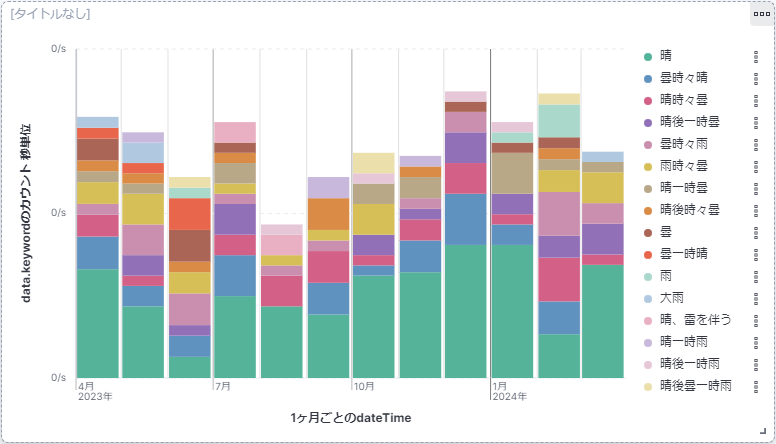
あとは、タイトルを入れるなり、グラフの大きさを変えるなり、グラフ右上のボタンからパネルをクローン(複製)するなりして、ダッシュボードを整えて行きます。
おわりに
いかがだったでしょうか。データ分析というまでには行きませんでしたが、そこら辺にあるデータを簡単に可視化できることが分かったかと思います。
Web アプリケーションを開発されている方などは、API にアクセスされた際のログを保存しておき、定期的にログデータをこういった Elasticsearch などのツールに投入することにより、どの機能が良く使われているか、日々どのくらいのユーザーさんに使っていただいているかなど、可視化しつつ分析することができるかと思います。
分析したデータを見る習慣、活用する道筋ができてきた際には、Elastic Cloud などのマネージされたセキュアな環境を利用していくのも良いでしょう。
まずはこうした小さな一歩から、データの分析・活用を始めてみましょう。
KENTEMでは、様々な拠点でエンジニアを大募集しています!
建設×ITにご興味頂いた方は、是非下記のリンクからご応募ください。
hrmos.co
hrmos.co
hrmos.co
hrmos.co